Decision trees are powerful tools used in machine learning and data analysis to make informed decisions based on input data. They are versatile, intuitive, and widely employed in various fields such as finance, healthcare, and marketing. In this article, we will explore the concept of decision trees, how they work, and their applications.
Part 1. What is a Decision Tree?
A decision tree is a tree-like model that represents decisions and their possible consequences. It consists of nodes representing decision points, branches representing possible outcomes, and leaves representing the final decision or outcome. The decision tree algorithm recursively splits the data into subsets based on the most significant attribute at each decision node.
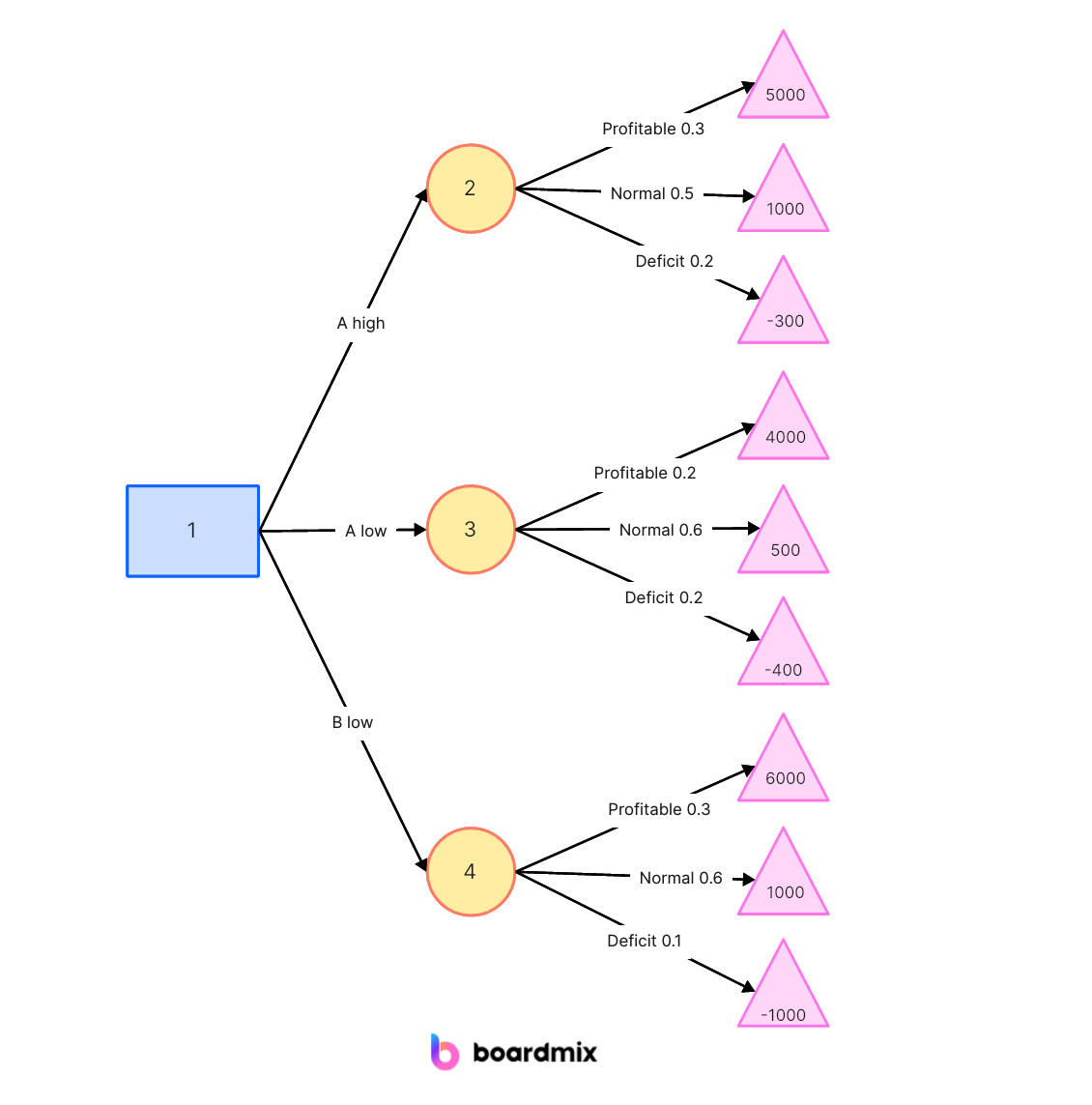
The decision tree algorithm recursively splits the dataset into subsets based on the selected features and their thresholds, aiming to create branches that result in homogeneous subsets with respect to the target variable. This process continues until a stopping criterion is met, such as reaching a specified depth or achieving a minimum number of instances in a leaf node.
Decision trees are easy to understand and interpret, and they can handle both numerical and categorical data. However, they are prone to overfitting, especially when the tree is deep and captures noise in the training data. Techniques like pruning and limiting tree depth can help mitigate overfitting.
Part 2. How Do Decision Trees Work?
Decision trees work by recursively splitting the dataset into subsets based on the values of input features. The goal is to create a tree structure that makes decisions or predictions about a target variable. Here's a step-by-step explanation of how decision trees work:
Selecting the Best Feature:
At each internal node of the tree, the algorithm selects the feature that provides the best split. The "best split" is determined by a criterion such as Gini impurity (for classification problems) or mean squared error (for regression problems).
The algorithm considers all features and their possible thresholds to find the split that maximally separates the data into homogeneous subsets regarding the target variable.
Splitting the Dataset:
Once the best feature and threshold are chosen, the dataset is divided into two subsets based on this split. Instances that satisfy the condition go to one child node, while instances that do not go to the other child node.
Repeating the Process:
The process is then applied recursively to each subset at the child nodes. The algorithm selects the best feature for each subset and creates further splits.
This recursive process continues until a stopping criterion is met, such as reaching a specified depth, having a minimum number of instances in a leaf node, or achieving a specific level of purity.
Assigning Predictions:
Once the tree is built, the leaf nodes contain the final decisions or predictions. For classification problems, the majority class in a leaf is assigned as the predicted class. For regression problems, the mean or median of the target variable in a leaf is used as the prediction.
Handling Categorical Variables:
Decision trees can handle both numerical and categorical features. For categorical features, the algorithm can create branches for each category, effectively splitting the data based on the categories.
Dealing with Overfitting:
Decision trees are prone to overfitting, capturing noise in the training data. To address this, techniques like pruning (removing branches that do not provide significant improvements) and setting a maximum depth for the tree are employed.
In summary, decision trees make decisions by recursively splitting the dataset based on the values of input features, with the goal of creating a tree structure that accurately predicts the target variable while avoiding overfitting. The process involves selecting the best feature at each internal node, splitting the data accordingly, and repeating the process until a stopping criterion is met.
Part 3. How to Build a Decision Tree
Building a decision tree involves a step-by-step process, and there are various algorithms to construct decision trees. One of the commonly used algorithms is the CART (Classification and Regression Trees) algorithm. Here's a general guide on how to build a decision tree:
- Collect and Prepare Data: Gather a dataset that includes both input features and the corresponding target variable you want to predict. Clean and preprocess the data, handling missing values and encoding categorical variables if necessary.
- Choose a Splitting Criterion: Select a criterion to measure the impurity or homogeneity of a node. Common criteria for classification problems include Gini impurity and entropy, while mean squared error is often used for regression problems.
- Select the Best Split: Determine the feature and threshold that result in the best split based on the chosen criterion. This involves evaluating the impurity or error reduction for each possible split.
- Split the Data: Divide the dataset into two subsets based on the selected feature and threshold. Instances that meet the condition go to one branch, while others go to the other branch.
- Recursively Repeat the Process: Apply the same process recursively to each subset, selecting the best feature and threshold for each node until a stopping criterion is met.
- Stopping Criteria: Decide on stopping criteria to prevent overfitting. Common stopping criteria include Maximum tree depth. Minimum number of instances in a leaf node. A threshold for impurity reduction.
- Assign Predictions: At the leaf nodes, assign predictions based on the majority class for classification or the mean (or median) for regression.
- Interpret the Tree: Once the tree is built, interpret it to understand the decision-making process. You can visualize the tree to see how features contribute to predictions.
- Test and Evaluate: Test the decision tree on a separate test dataset to evaluate its performance. Calculate metrics such as accuracy, precision, recall, or mean squared error, depending on the problem.
Part 4. Free Decision Tree Template
Boardmix introduces an innovative and user-friendly decision tree tool that simplifies complex decision-making processes. This feature allows users to visually map out, explore, and understand multiple possible outcomes of a decision before making a choice. By creating a structured approach to problem-solving, Boardmix's decision tree tool not only enhances clarity but also promotes collaboration by enabling teams to work together in real time. Whether you're strategizing business moves or planning project workflows, our decision tree tool can help streamline your process and drive informed decisions.
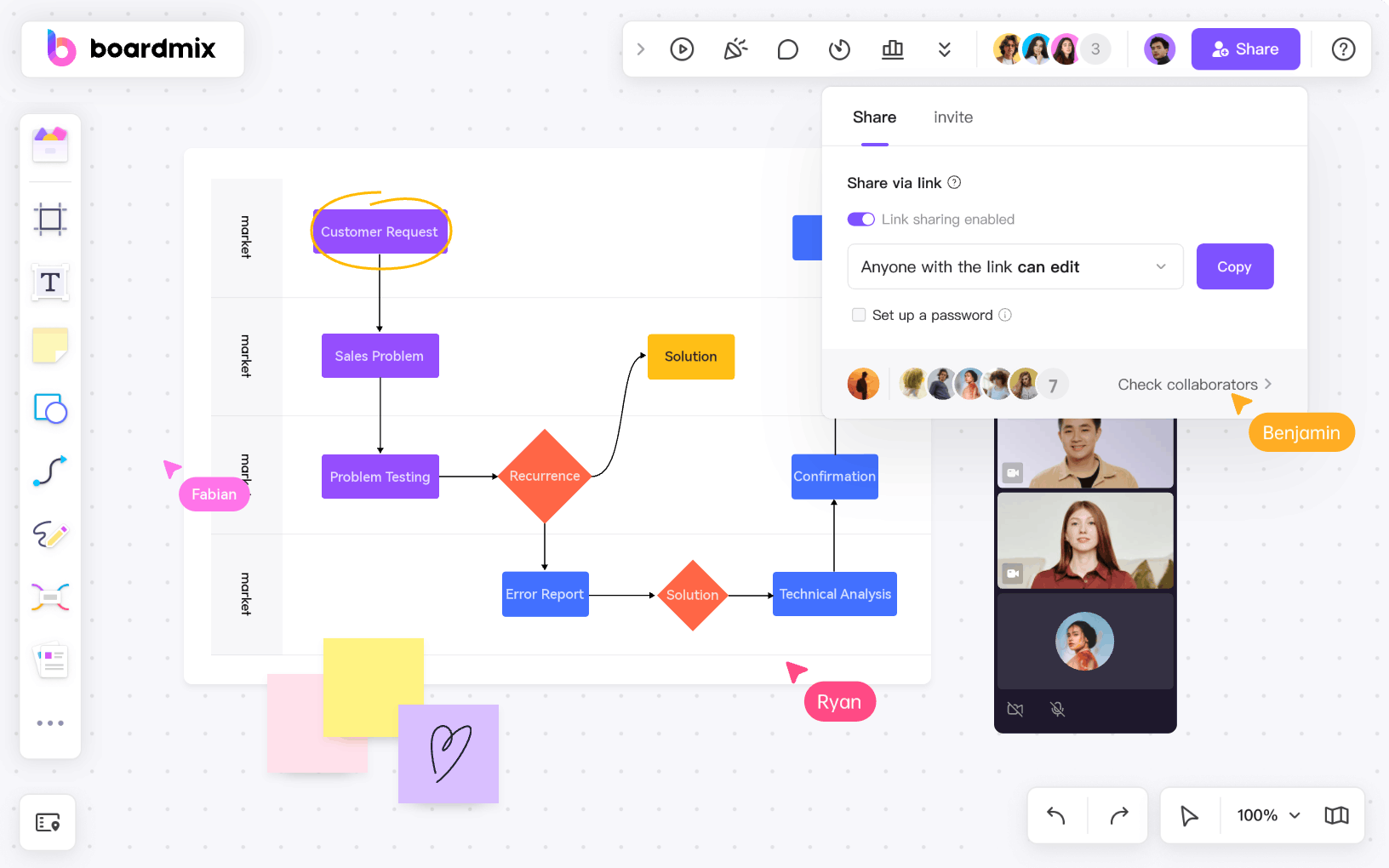
How to Build a Decision Tree with Boardmix
1. Start by opening a new Boardmix board.
2. Select the 'Decision Tree' template from our extensive library of templates.
3. Begin by identifying your main decision or problem at the left side of the tree.
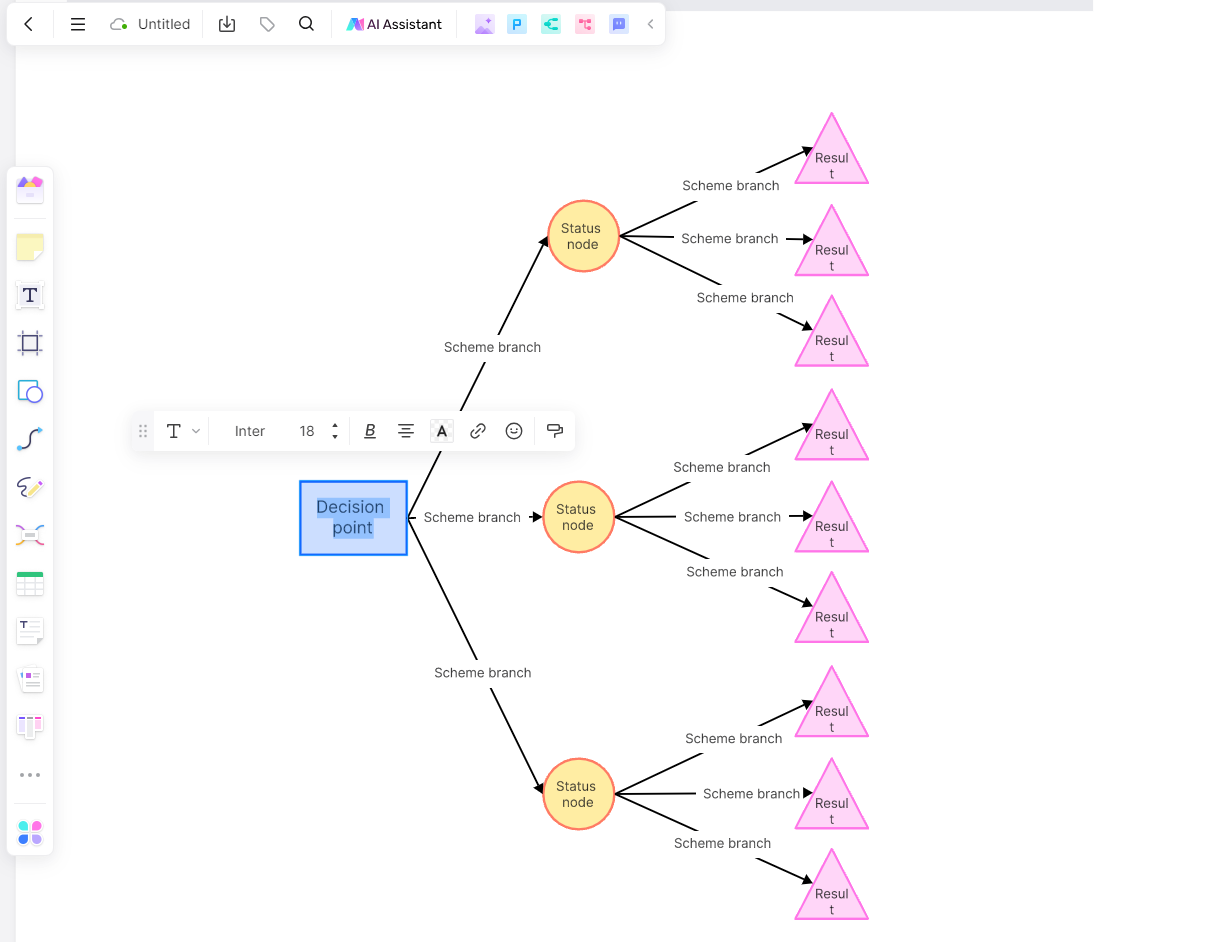
4. From there, branch out to possible options or outcomes.
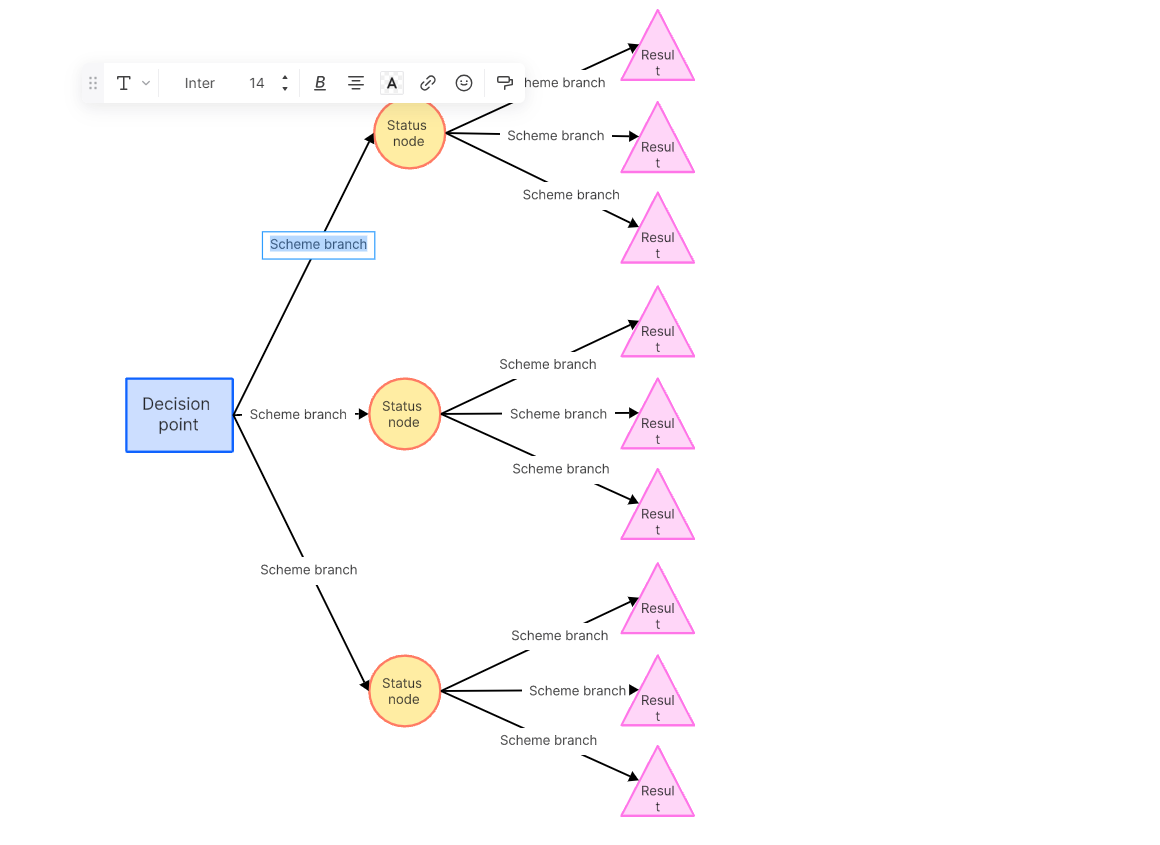
5. Continue branching out with further possibilities until you've mapped out all potential outcomes.
6. Collaborate in real-time with your team to weigh the pros and cons, add notes, and make informed decisions.
Part 5. Applications of Decision Tree
Decision trees find applications in various fields due to their versatility, interpretability, and ability to handle both classification and regression tasks. Some common applications of decision trees include:
Classification Problems: Decision trees are widely used for classification tasks. Examples include spam detection, credit scoring, medical diagnosis, and sentiment analysis in natural language processing.
Regression Problems: Decision trees can be applied to regression problems, such as predicting house prices, sales forecasting, and any scenario where the goal is to predict a continuous numerical value.
Medical Diagnosis: Decision trees are used in healthcare for medical diagnosis and prognosis. They can help identify diseases, recommend treatments, and predict patient outcomes based on various medical parameters.
Finance: In finance, decision trees are used for credit scoring, fraud detection, and investment decision-making. They help assess the creditworthiness of individuals, detect potentially fraudulent transactions, and make investment decisions based on market conditions.
Marketing and Customer Relationship Management (CRM): Decision trees are employed in marketing to segment customers, personalize marketing campaigns, and predict customer behavior. CRM applications use decision trees to optimize customer interactions and improve customer satisfaction.
Image and Speech Recognition: Decision trees can be part of systems for image recognition and speech processing. They help classify and interpret visual or auditory data, contributing to applications like facial recognition and voice command systems.
These are just a few examples, and the versatility of decision trees makes them applicable in various domains where decision-making based on data patterns is required.
Part 6. Advantages of Decision Trees
Decision trees offer several advantages, making them a popular choice in various applications across different industries. Here are some key advantages of decision trees:
Interpretability: Decision trees provide a transparent and easy-to-understand representation of decision-making processes. The tree structure visually displays how decisions are made at each node, making it accessible to non-experts and facilitating the interpretation of results.
Handle Both Numerical and Categorical Data: Decision trees can handle a mix of numerical and categorical features without requiring extensive preprocessing. This flexibility makes them suitable for a wide range of datasets.
No Assumption of Linearity: Decision trees do not assume a linear relationship between features, making them effective in capturing complex, non-linear patterns in the data. This is in contrast to linear models that assume a linear relationship between input variables.
Require Minimal Data Preparation: Decision trees are less sensitive to outliers and do not require extensive data preprocessing. They can handle missing values without a significant impact on their performance.
Automatically Handle Feature Selection: Decision trees can automatically select relevant features by giving more importance to features that contribute to the model's ability to split and classify the data effectively. This can simplify the feature selection process.
Handle Interaction Effects: Decision trees naturally capture interaction effects between different features, allowing them to model complex relationships in the data where the effect of one feature depends on the value of another.
It's important to note that while decision trees have these advantages, they also have limitations, such as being prone to overfitting. Techniques like pruning and using ensemble methods can help mitigate some of these challenges.
Conclusion
Decision trees are a valuable tool in the realm of machine learning and data analysis. Their simplicity, interpretability, and effectiveness make them a popular choice for solving a wide range of problems. Understanding the principles behind decision trees is essential for harnessing their potential and making informed decisions in complex scenarios.
Experience the ease and efficiency of decision-making with Boardmix's intuitive decision tree tool. With real-time collaboration features, a vast library of templates, and the ability to visualize all potential outcomes, Boardmix is your ultimate solution for strategic planning. Don't just make decisions - make informed decisions with Boardmix.